Əsrin Proqramlaşdırma Mühiti - Kompilyator
Əsrin Proqramlaşdırma Dilinin Kompiyatoru C++ proqramlaşdırma dilində tərtib olunub və
hazırkı buraxılış (0.0.1) təxminən 13000 sətir koddan ibarətdir. Kompilyatorun qaynaq kodları
ilə aşağıdakı keçiddən tanış ola bilərsiniz.
Əsrin Kompilyatorunun Qaynaq Kodları
Kompilyasiya prosesi aşağıdakı mərhələlərdən ibarətdir:
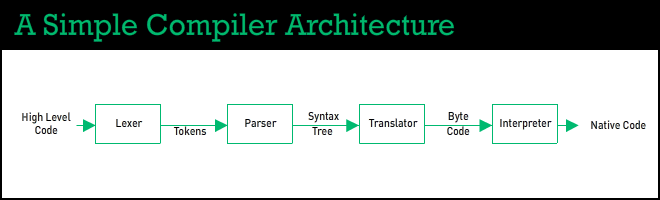
- Mətnin tokenlərə çevrilməsi
- Leksik səhvlərin yoxlanması
- Tokenlər ardıcıllığından parsinq ağacının qurulması
- Sintaksis səhvlərin yoxlanması
- Simvollar Cədvəllərinin qurulması
- Semantik səhvlərin yoxlanması
- İcraolunma kodunun generasiyası
Mətni Hissələrə - Tokenlərə Parçalama
Tokenlərə parçalama (bunu lexer və ya tokenayzer həyata keçirir) kompilyasiyanın ilk mərhələsidir. Bu zaman nisbətən sadə qrammatikaya malik requlyar dillərdən istyifadə olunur. Requlyar dillərin tanınması DFA - Deterministik Finit State Automata tərəfindən aparılır.
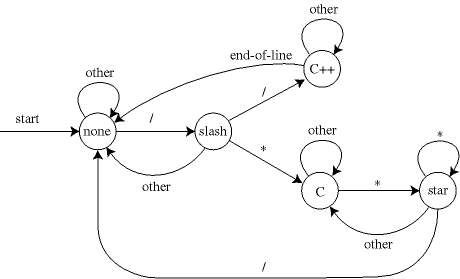
Lexerin vəzifəsi proqram mətnini məntiqi hissələrə - tokenlərə parçalamaqdır. Misal üçün tutaq ki, aşağıdakı kimi proqram mətni verilib:
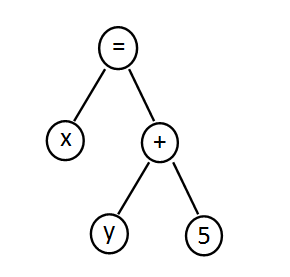
x = y + 5 ;
Bu mətn aşağıdakı tokenlərə parçalanır:
| Dəyişən | x |
| Bərabərlik | = |
| Dəyişən | y |
| Üstəgəl | + |
| Ədəd | 5 |
| Nöqtəverül | ; |
Növbəti mərhələ parsing mərhələsidir. Bu mərhələdə tokenlər ardıcıllığından
parsing ağacı qurulur.
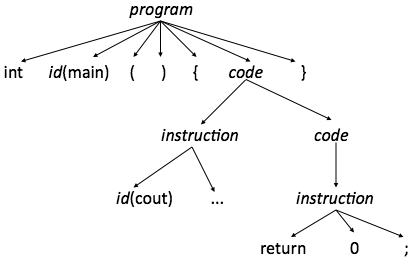
Yuxarıdakı tokenlər ardıcıllığına uyğun parsing ağacı
aşağıdakı kimidir:
Əsrin dili Context Free dillərə aiddir. Context Free dillərin parsinqi üçün müxtəlif alqoritmlər mövcuddur. Onlardan ən güclüsü LR(k) parsing alqoritmidir. LR (k) alqoritmi Shift/Reduce cədvəlini tələb edir.

LR parsinq cədvəli mətni O(n) mürəkkəbliyi ilə ancaq bir dəfə oxumaqla tanıyır , başqa sözlə parsinq ağacın qurur. Lakin LR parser cədvəlinin qurulması öz növbəsində verilmiş dil üçün First and Follow çoxluqlarının qurulmasını tələb edir. Verilmiş dil üçün First and Follow çoxluqlarının qurulması işi heç də asan iş deyil.
Hal-hazırda bunun üçün avtomatlaşdırılmış vasitələrdən (misal üçün flex/bison) istifadə olunur.
Əsrin dilinin parsinqi üçün biz avtomatlaşdırılmış vasitələrdən imtina etməli olduq. Səbəb isə odur ki, avtomatlaşdırılmış vasitələr tərtib etdiyi parser üçün səhv ismarıclarını İngilis dilində verir. Buna görə də parser alqoritmini özümüz tərtib etməli olduq, lakin uzun sürən cəhdlərdən sonra Shift/Reduce cədvəli ilə bağlı problemlərə görə LR(k) alqorimindən imtina etməli olduq.
Context Free dillərin parsinqi üçün istifadə olunan digər geniş yayılmış alqoritm isə Top Down Recursiv parsing alqoritmidir(Yuxarıdan Aşağı Rekusiv). TopDown ilə bəzi uğurlu cəhdlərimiz olsa da şərt operatorunun 11 qrammatik qaydadan ibarət olması rekursiv tanınmanı əngəllədi və debaq da çox çətin oldu.
Bottom Up Parsing metodu isə işə yaradı. BottomUp ilə dili tanıyan parseri qurduq və sınaqlar da çox uğurlu oldu.
Bottom Up alqoritmi Əsrin dili üçün tamamilə sıfırdan tərtib olunub və parse.cpp faylında realizə olunub.
Parseinq ağacı qurulduqdan sonra simvollar cədvəlləri qurulur, səhvlər yoxlanılır və kod generasiya olunur. Generasiya olunan kod isə icraçı tərəfindən icra olunur. Kod generasiyası və icrası barədə daha ətraflı məlumatı İcraçı səhifəsindən əldə edə bilərsiniz.